An API is protected with a Client ID Enforcement policy and uses the default configuration. Access is requested for the client application to the API, and an approved contract now exists between the client application and the API. How can a consumer of this API avoid a 401 error "Unauthorized or invalid client application credentials"?
A. Send the obtained token as a header in every call
B. Send the obtained: client_id and client_secret in the request body
C. Send the obtained clent_id and clent_secret as URI parameters in every call
D. Send the obtained clent_id and client_secret in the header of every API Request call
Explanation:
When using the Client ID Enforcement policy with default settings,
MuleSoft expects the client_id and client_secret to be provided in the URI parameters of
each request. This policy is typically used to control and monitor access by validating that
each request has valid credentials. Here’s how to avoid a 401 Unauthorized error:
Refer to the exhibit. An organization is running a Mule standalone runtime and has
configured Active Directory as the Anypoint Platform external Identity Provider. The organization does not have budget for other system components.
What policy should be applied to all instances of APIs in the organization to most
effecuvelyKestrict access to a specific group of internal users?
A.
Apply a basic authentication - LDAP policy; the internal Active Directory will be
configured as the LDAP source for authenticating users
B.
Apply a client ID enforcement policy; the specific group of users will configure their client applications to use their specific client credentials
C.
Apply an IP whitelist policy; only the specific users' workstations will be in the whitelist
D.
Apply an OAuth 2.0 access token enforcement policy; the internal Active Directory will be configured as the OAuth server
Apply a basic authentication - LDAP policy; the internal Active Directory will be
configured as the LDAP source for authenticating users
Explanation: Explanation
Correct Answer: Apply a basic authentication - LDAP policy; the internal Active Directory
will be configured as the LDAP source for authenticating users.
*****************************************
>> IP Whitelisting does NOT fit for this purpose. Moreover, the users workstations may not
necessarily have static IPs in the network.
>> OAuth 2.0 enforcement requires a client provider which isn't in the organizations system
components.
>> It is not an effective approach to let every user create separate client credentials and
configure those for their usage.
The effective way it to apply a basic authentication - LDAP policy and the internal Active
Directory will be configured as the LDAP source for authenticating users.
Reference: https://docs.mulesoft.com/api-manager/2.x/basic-authentication-ldap-concept
Several times a week, an API implementation shows several thousand requests per minute
in an Anypoint Monitoring dashboard, Between these bursts, the
dashboard shows between two and five requests per minute. The API implementation is
running on Anypoint Runtime Fabric with two non-clustered replicas, reserved vCPU 1.0
and vCPU Limit 2.0.
An API consumer has complained about slow response time, and the dashboard shows the
99 percentile is greater than 120 seconds at the time of the complaint. It also shows greater than 90% CPU usage during these time periods.
In manual tests in the QA environment, the API consumer has consistently reproduced the
slow response time and high CPU usage, and there were no other API requests at
this time. In a brainstorming session, the engineering team has created several proposals
to reduce the response time for requests.
Which proposal should be pursued first?
A. Increase the vCPU resources of the API implementation
B. Modify the API client to split the problematic request into smaller, less-demanding requests
C. Increase the number of replicas of the API implementation
D. Throttle the APT client to reduce the number of requests per minute
Which component monitors APIs and endpoints at scheduled intervals, receives reports about whether tests pass or fail, and displays statistics about API and endpoint performance?
A. API Analytics
B. Anypoint Monitoring dashboards
C. APT Functional Monitoring
D. Anypoint Runtime Manager alerts
Explanation:
What Mule application deployment scenario requires using Anypoint Platform Private Cloud Edition or Anypoint Platform for Pivotal Cloud Foundry?
A.
When it Is required to make ALL applications highly available across multiple data centers
B.
When it is required that ALL APIs are private and NOT exposed to the public cloud
C.
When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data
D.
When ALL backend systems in the application network are deployed in the
organization's intranet
When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data
Explanation: Explanation
Correct Answer: When regulatory requirements mandate on-premises processing of EVERY data item, including meta-data.
*****************************************
We need NOT require to use Anypoint Platform PCE or PCF for the below. So these
options are OUT.
>> We can make ALL applications highly available across multiple data centers using
CloudHub too.
>> We can use Anypoint VPN and tunneling from CloudHub to connect to ALL backend
systems in the application network that are deployed in the organization's intranet.
>> We can use Anypoint VPC and Firewall Rules to make ALL APIs private and NOT
exposed to the public cloud.
Only valid reason in the given options that requires to use Anypoint Platform PCE/ PCF is -
When regulatory requirements mandate on-premises processing of EVERY data item,
including meta-data
In which layer of API-led connectivity, does the business logic orchestration reside?
A.
System Layer
B.
Experience Layer
C.
Process Layer
Process Layer
Explanation: Explanation
Correct Answer: Process Layer
*****************************************
>> Experience layer is dedicated for enrichment of end user experience. This layer is to
meet the needs of different API clients/ consumers.
>> System layer is dedicated to APIs which are modular in nature and implement/ expose
various individual functionalities of backend systems
>> Process layer is the place where simple or complex business orchestration logic is
written by invoking one or many System layer modular APIs
So, Process Layer is the right answer.
Refer to the exhibit.
A.
Option A
B.
Option B
C.
Option C
D.
Option D
Option D
Explanation: Explanation
Correct Answer: XML over HTTP
*****************************************
>> API-led connectivity and Application Networks urge to have the APIs on HTTP based
protocols for building most effective APIs and networks on top of them.
>> The HTTP based APIs allow the platform to apply various varities of policies to address
many NFRs
>> The HTTP based APIs also allow to implement many standard and effective
implementation patterns that adhere to HTTP based w3c rules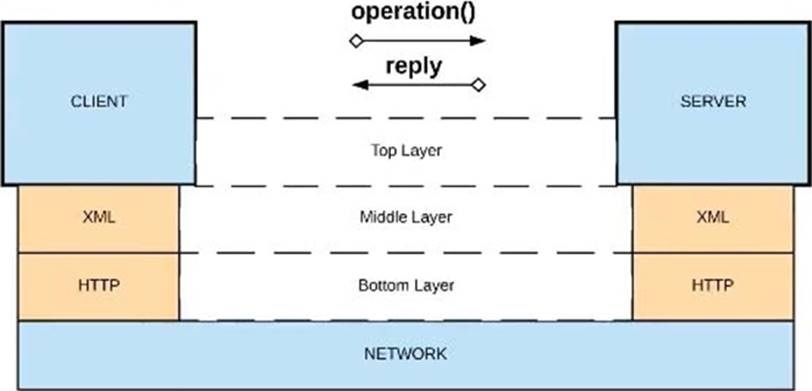
An API with multiple API implementations (Mule applications) is deployed to both CloudHub and customer-hosted Mule runtimes. All the deployments are managed by the MuleSoft-hosted control plane. An alert needs to be triggered whenever an API implementation stops responding to API requests, even if no API clients have called the API implementation for some time. What is the most effective out-of-the-box solution to create these alerts to monitor the API implementations?
A. Create monitors in Anypoint Functional Monitoring for the API implementations, where each monitor repeatedly invokes an API implementation endpoint
B. Add code to each API client to send an Anypoint Platform REST API request to generate a custom alert in Anypoint Platform when an API invocation times out
C. Handle API invocation exceptions within the calling API client and raise an alert from that API client when such an exception is thrown
D. Configure one Worker Not Responding alert.in Anypoint Runtime Manager for all API implementations that will then monitor every API implementation
Explanation:
In scenarios where multiple API implementations are deployed across
different environments (CloudHub and customer-hosted runtimes), Anypoint Functional
Monitoring is the most effective tool to monitor API availability and trigger alerts when an
API implementation becomes unresponsive. Here’s how it works:
| Page 3 out of 19 Pages |
| Mulesoft MCPA-Level-1 Exam Questions Home | Previous |
Contact Us - Privacy Policy ... Copyright © - All Rights Reserved